Georgia Tech researchers say non-English speakers shouldn't rely on chatbots like ChatGPT to provide valuable health care advice. A team of researchers from the College of Computing at Georgia Tech has developed a framework for assessing the capabilities of large language models (LLMs). Ph.
D. students Mohit Chandra and Yiqiao (Ahren) Jin are the co-lead authors of the paper "Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Health care Queries." The paper is published on the arXiv preprint server.

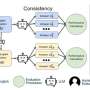
Their paper's findings reveal a gap between LLMs and their ability to answer health-related questions. Chandra and Jin point out the limitations of LLMs for users and developers but also highlight their potential. Their XLingEval framework cautions non-English speakers from using chatbots as alternatives to doctors for advice.
However, models can improve by deepening the data pool with multilingual source material such as their proposed XLingHealth benchmark. "For users, our research supports what ChatGPT's website already states: chatbots make a lot of mistakes, so we should not rely on them for critical decision-making or for information that requires high accuracy," Jin said. "Since we observed this language disparity in their performance, LLM developers should focus on improving accuracy, correctness, consistency, and reliability in other languages," Jin said.
Using XLingEval, the researchers found chatbots are less accurate in Spanish, Chinese, and.